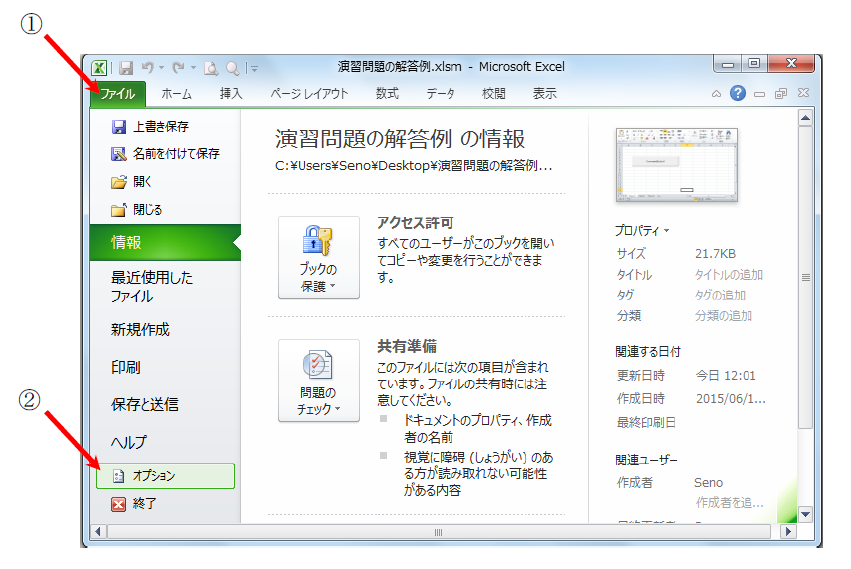
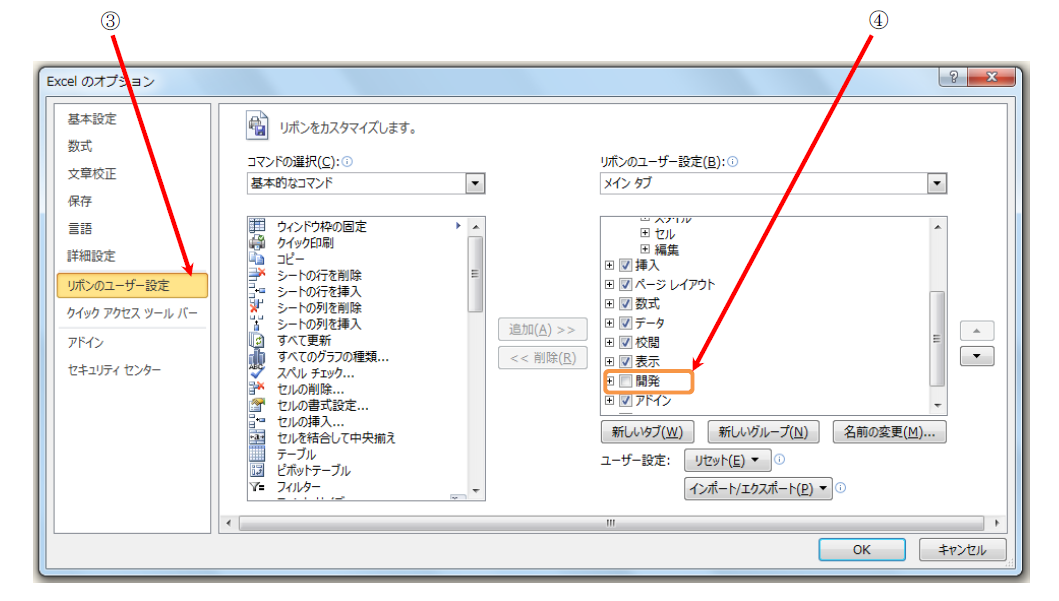
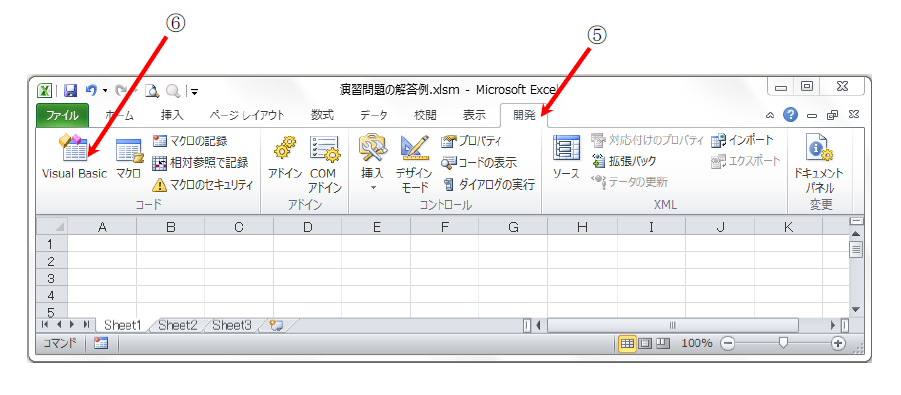
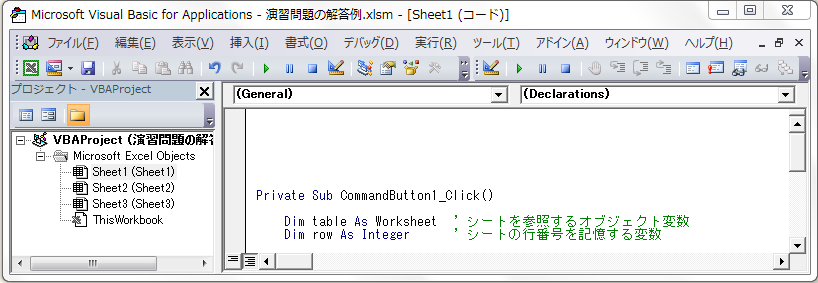
この講座は、普段、C言語でソフトウェアを開発されている「組み込みソフトウェア技術者」の皆様に向けて、pythonの活用例をご紹介する講座です。その第1回では、pythonの言語仕様について、C言語と比較しながら、ポイントをご紹介します。
関数
pythonでは、C言語と同じく、関数を記述し、実行できます。ただしC言語では、関数が必須であるのに対して、pythonでは関数を書いても良いし、書かなくても良い…という違いがあります。関数を作成せずにpythonのソースコードを書いた場合、記述順に従い、(制御文で分岐させない限り)基本、上から下に順番に実行されます。
(補足)
ソースファイルの上から順番に処理を書く場合でも、その途中に、必要に応じてに関数を書く事も可能です。この場合は、関数「以外」の処理が上から順に実行され、関数の中身は「関数呼び出し」が記述された場合のみ、その呼び出し箇所から呼ばれ、実行されます。
pythonの関数の記述例を以下に示します。
def addAndCheck_over100(var1, var2):
result = var1 + var2
isOver100 = False
if (result > 100):
isOver100 = True
return (result, isOver100)
- 関数先頭の書式は「def 関数名(引数, …):」です。末尾のコロン’:’は必須です。引数が無い場合は括弧()内は空にします。
- 引数や戻り値の「型宣言」は不要です。「型」については、後の節で解説します。
- pythonでは、変数を使用する際、事前に宣言する必要は無く、いきなり「初期化」から記述できます。
- pythonの関数の大きな特徴は、複数の値を「戻り値」として返せる点です。
上記した関数の呼び出し元の記述例は、以下です。複数の戻り値のコピー先をカンマ(,)で区切って、左から順に並べます。
value, isOver = Add_andCheck_over100(48, 32)
型宣言
C言語では、変数を宣言する際、必ずその「型」を宣言しましたが、pythonでは型宣言は不要です。
pythonにおける変数の型は、その変数に値を「代入」した時に決定されます。また既に値を代入した変数に対して、別の型の値を代入すると、その時点で変数の型が変わります。
var1 = 10
print(var1)
print(type(var1))
var1 = "ABC"
print(var1)
print(type(var1))
上記したpythonソースコード中の「type()」は、引数で指定した変数の「型名」を文字列で返す関数です。上記のソースを実行した場合、画面には以下が表示されます。
10
<class 'int'>
ABC
<class 'str'>
同じ変数var1に対して、異なる型である「文字列型」の値を代入したことで、変数の型がint型から文字列(str)型に変化しています。ただ上記のように、同じ変数に異なる型の値を代入するようなソースコードを積極的に書く必要は無く、pythonの言語仕様として、そういう特徴がある..という事だけ覚えて頂ければと思います。
ブロック
C言語では、ブロックを{}で表現しましたが、pythonでは「インデント」で表現します。すなわち、同じ階層の「インデント」が同じブロックになります。
if (a > 10):
if (b > 20):
print("OK!")
インデントは、タブまたは半角スペースで記述できますが、同じ階層のインデントは、同じ文字で記述する必要があります。たとえばタブを使った場合、その階層のインデントは、全てタブで段下げする必要がありますし、半角スペースを使った場合は、全て半角スペースで段下げする必要があります。
タブとスペースは、無理に混在させる必要は無いと思いますので(C言語でも同様)、普段お使いの文字で段下げされれば良いと思います。
文字
この後にご紹介するpythonの活用法では、テキストファイル/CSVファイル/EXCELファイル等のファイルを読み込み、処理する活用法をご紹介する予定です。それに向けた予備知識として、本節ではpythonにおける「文字」の扱いについて説明します。
C言語では「文字」が連続したものが「文字列」ですが、pythonでは1文字だけを表現する「文字型(char型)」は存在しません。pythonにおいて「文字」を扱う場合は「1文字だけの文字列」として扱う必要があります。この点は、C言語と大きく異なる点ですが、慣れてくると、特に不都合を感じる事はありません。
たとえば、文字列を先頭から1文字ずつ参照し、文字’A’ と同じか判定したい場合は、以下のように記述します。
str1 = "ABC" # C言語の記述と似ている。ただし文字列終端のnull文字('\0')は存在しない。
length = len(str1) # 文字列のバイト長は関数len で取得可能。結果は3。
for i in range(length): # iの値0から2でループさせたい場合 ※for文と range()は後節で解説
if (str1[i] == "A"): # []は「スライス」と呼ばれる。※後節で解説
print("Matched! at index:%d" % i)
(補足)
- 文字列の前後を囲む文字は ” でも ‘ でも、どちらでも使用できます。
- 文字列から「1文字だけの文字列」を取り出す場合は[]を使用します。これは「スライス」と呼ばれるものです。
スライスについては、後の節で解説します。
C言語では、1文字を判定(もしくは変換)する関数として、isdigit()、toupper() 等の関数が用意されていますが、pythonでは、同様の関数が「文字列全体」に対して用意されています。たとえば isdigit()は「文字列全体が全て10進数ならTrue、否ならFalseを返す」関数として用意されています。
toupper()は、pythonでは関数名がupper()に変わりますが、その機能は「アルファベットの小文字は大文字に変換し(それ以外の文字は変換せずに)、処理後の文字列を返す」関数として用意されています。
str1 = "abc1"
length = len(str1)
for i in range(length):
if (str1[i].isdigit() == True):
print("Digit! at index:%d" % i)
else:
convStr = str1[i].upper()
if (convStr == "A")
print("Matched! at index:%d" % i)
「クラス」と「メンバ関数」について
上記のソースにおいて、関数isdigit および 関数upperは、関数lenとは異なり、文字列型の変数str1の「変数名の後にピリオド’.’を付けて」その後に関数名を指定して呼び出しています。その理由は、関数isdigit および 関数upperは、文字列型の「クラス」に属する「メンバ関数」として実装されているためです。
C++やJava等、クラスが使えるプログラミング言語の経験のある方々にとっては、馴染みのあるこの「メンバ関数」ですが、この種の(オブジェクト指向の)プログラミング言語のご経験の無いC言語プログラマの方々にとっては、馴染みの薄い事柄だと思います。
ここで少しだけ「クラス」および「メンバ関数」について補足します。
- 「クラス」は、C言語における「構造体」に似ていますが、メンバとして「関数」が追加できます。
- メンバとして追加した関数を「メンバ関数」と呼びます。
- 「メンバ関数」では、(一般的には)他の「メンバ変数」の参照/変更に関わる処理を行います。
python において、どのような関数が関数lenのよう(グローバル関数のよう)に提供され、またどのような関数が「メンバ関数」として提供されているかは「こんな関数を使いたい」という「目的」が生じた時点で、ネット検索で確認してください。
配列(pythonでは「リスト」と呼びます)
pythonにおいても(C言語と同様に)配列が使用できます。pythonでは配列のことを「リスト」と呼びます。以下、リストの使用例を示します。
arr1 = [0,1,2] # リストを初期化
print(arr1) # [0, 1, 2] が表示される
arr1[1] = 100 # 1番目の要素を変更(インデックスはゼロ始まり)
print(arr1) # [0, 100, 2] が表示される
arr2 = arr1 # リストを別の変数にコピー ⇒中身では無く「参照」がコピーされ、同じ実体を指す
arr2[1] = 11 # コピー先の1番目の値を書き換えた後、以下でコピー元のリストを表示
print(arr1) # [0, 11, 2] が表示される(「参照」のコピー故、コピー元のリストも変化)
arr1.clear() # メンバ関数clearで全データを消去
print(arr1) # [] が表示される
arr1.append(101) # メンバ関数appendでデータを追加
print(arr1) # [101] が表示される
def func(arr, dt): # 引数arrでリストの「参照」を受け、引数dtで設定する値を受ける
arr[0] = dt # 0番目の要素を書き換え
func(arr1, 200) # 上記関数を呼び出す
print(arr1) # [200] が表示される
あるリストを別のリストに「代入」すると、中身が「コピー」されるのでは無く「参照」がコピーされます。すなわち「代入」した後は、コピー先、コピー元 共に、同じ「実体」を指すようになります。この特徴は「代入」だけで無く、「関数の引数」にリストを渡したときも同じです。
なお、この「参照」では無く、リストの中身をコピーしたいときもあると思います。この場合は、以下のように記述することで、「参照」では無く「中身がコピー」されます。
arr2 = [] #空のリストで初期化
arr2 += arr1 #そこに既存のリストarr1 の中身を追加(まとめて arr2 = [] + arr1 と書いても可)
ポインタ
pythonでは「ポインタ」は使えません。またJavaのような「参照」も、前節でご紹介した「リスト」等、一部の型でしか使えません。ですので、関数の引数に「整数型」や「文字列型」の変数アドレスを渡して、関数内で中身を「書き換える」こともできません。
この対策として、筆者は関数から「複数の戻り値」を返して、元の変数に「代入」する事で対処しています。
def proc(a, b, c):
b = a + b
c = b + c
a = c + a
return (a, b, c)
var1 = 1
var2 = 2
var3 = 3
var1, var2, var3 = proc(var1, var2, var3)
文字列のコピー
C言語では、strcpyやmemcpyを使って、文字列の中身をコピーしましたが、pythonでは「代入」によって文字列を「丸ごと」コピーできます。
str1 = "ABC"
str2 = str1
str2 = "012"
print(str1) # ABC が表示される
print(str2) # 012 が表示される
文字列は、一見するとC言語の配列のように見えますが、実は、文字列は「文字列(str)型」であり、リストとは異なり、「文字列中の一部の文字だけ書き換える」事はできません。たとえば以下は禁止されます。
str1 = "ABC"
str1[1] = 'b'
このような場合は、後節で説明する「スライス」を使って新たな文字列を作成し、その新たに作成した文字列「全体」をコピーし直します。
newStr = str1[0:1] + "b" + str1[2:]
str1 = newStr
スライス
先のpythonのソースコード中の[]は「スライス」と呼ばれ、文字列や配列(pythonでは配列のことを「リスト」といいます)の「一部を取り出す」ために使用します。書き方は以下です。
配列[開始位置:終了位置]
- 開始位置は、先頭を「ゼロ番目」とするインデックス番号で指定します。
- 終了位置も先頭を「ゼロ番目」とするインデックス番号で指定しますが、注意点として「終了位置より1つ大きい位置を指定する」必要があります。
- 開始位置、終了位置、共に省略できます。
- コロン’:’と終了位置を省略し、開始位置だけ指定することも可能です。
たとえば文字列”ABC”が格納された変数str1の先頭2文字分を別物の文字列として取り出したい場合は str1[0:2] と指定します。
開始位置を省略した場合は、ゼロが指定されたと見なされます。終了位置を省略した場合は最後、すなわち最終位置より1つ大きい位置が指定されたと見なされます。
この場合は開始位置から1つ分の要素だけ指定したと見なされます。
(補足)
以前の節でご紹介したとおり、文字列の場合は「別物の文字列」が生成され、またリストの場合は「参照」が取り出されます。リストの場合は、スライスで取り出した一部の中身を「書き換える」ことが可能です。
list1 = [0,1,2,3]
list1[1] = 101 #書き換え可能
list1[2:] = [102,103] #書き換え可能
for文
先のpythonのソースコード中の「for i in range(length):」は、C言語における「for (int i = 0; i < length; i++) {」に相当する記述でした。
pythonにおけるfor文では「for 変数名 in」の後に「配列」「リスト」等の「データの集合」を指定します。
たとえば先のpythonのソースコードは、文字列の先頭から1文字ずつ、別物の(1文字から成る)文字列として、スライスを使って取り出していましたが、これと同じ処理は、以下のように記述できます。
for chStr in str1: # 文字列str1の先頭から1つずつ要素を取り出す
if (chStr == “A”):
ただこの方法では「何番目か」を」示すインデックス番号が取得できないです。このような用途に対して、pythonでは、以下の記述も使えます。
for i, chStr in enumerate(str1): # 文字列str1の先頭から1つずつ要素を取り出す
if (chStr == "A"):
print("Matched! at index:%d" % i)
range()
本節では先のpythonのソースコードのfor文で使用した「range()」について説明します。rangeは「range型(クラス)」で、range()は「range型のオブジェクトの実体を生成して返す」関数です。
range型は、引数で指定した値に応じて、連続した値を要素として持つデータ集合です。たとえば「range(3)」として指定すると、この関数は「0,1,2」の連続する3つの値を持つオブジェクトを返します。
rangeは、for文以外ではあまり使う事が無いと思いますので、rangeについての説明は、この程度に留めます。この説明をご覧になられて混乱された方は、慣れるまで rangeは、上記したpythonソースの例のように「for文でしか使わない」と割り切って使って頂いて大丈夫と思います。
書式変換
C言語では、printf文において”%d” や “%x” 等の書式変換が使用できますが、pythonでも、基本、同様の書式変換が可能です。
書式付き文字列 % (引数1, 引数2, 以降も続く)
引数が1つの場合は、 書式付き文字列 % 引数1として記述し、%の後の括弧()は不要です。pythonでは、上記の書式変換は、print関数に限らず「文字列に対する操作」として使用できます。よって前の節に記述したpythonの画面表示のソースコードは、以下のように書き換える事も可能です。
resultStr = "Hit at index:%d" % i
print(resultStr)
(補足)関数printは、C言語のprintfに相当する画面表示関数です。
ソースファイルの実行方法
- pythonのソースファイルの拡張子は.pyです。この拡張子でソースファイルを作成してください。
- pythonのソースファイルは事前にコンパイルする必要は無く、いきなり、DOSプロンプト上で「python ソースファイル名.py
」で実行できます。 - pythonのソースファイル実行時、言語仕様 他に違反したコード記述を実行した場合、「例外」が発生し、実行が途中終了します。
その際、「例外」に至るまでの「関数呼び出し」の履歴と、エラー内容が画面表示されます。
その他の言語仕様について
以上、第1回の講座では、pythonの言語仕様について、C言語と比較する形で簡単にご紹介しました。
実際にpythonでプログラムを作成する上では、上記以外にも、知っておいた方が良い事柄が沢山あります。以下では思い付いた事柄を列挙します。詳細については、ネット検索でご確認ください。
- 日本語の文字エンコードは、デフォルトはUFT-8。これをシフトJISに変更したい場合は、ソースファイル先頭にコメントとして、以下を記述すれば良いです。
# -*- coding: sjis -*-
- pythonではfor文以外にも、if文、elif文、else文、while文 の制御文が使用できます。
- switch~case文に相当する制御文として、Pythonの3.10以降ではmatch~case文が使用できるようになりました。
- 関数の先頭行や、if文、elif文、else文、while文 の末尾には、コロン(:)が必要です。
- ループ文のブロック内では、continue文、break文が使用できます。
- ブール値(true/false)には、大文字から始まる True、False が使用できます。
- C言語の && || は、and or と記述する必要があります。
- インクリメント、デクリメントは使用できません。代替として、+= や -= を使用します。
- #define は使えません。代替としては、大文字で変数を宣言し、通常の変数のように初期化して使用する記述が良く使われます。
- #ifも使えません。筆者は代替として通常のif文を使っています。例:「#if 0」は「if (False)」等
- 豊富なライブラリが用意されています。pythonのインストール時にインストールされなかったライブラリは、DOSプロンプト上で実行する「pip」コマンドでいつでも追加でインストールできます。
ただ古いpythonでも実行できるソースコードを書くならmatch~case文は使わずに、if,elif,else文を並べて、同じ変数値を繰り返し比較する必要があります。
これを忘れると、実行時にエラー表示され、実行できません。
「こんなライブラリが欲しい」と思われた時点で、ネット検索で確認してください。お目当てのライブラリが見つかると思います。